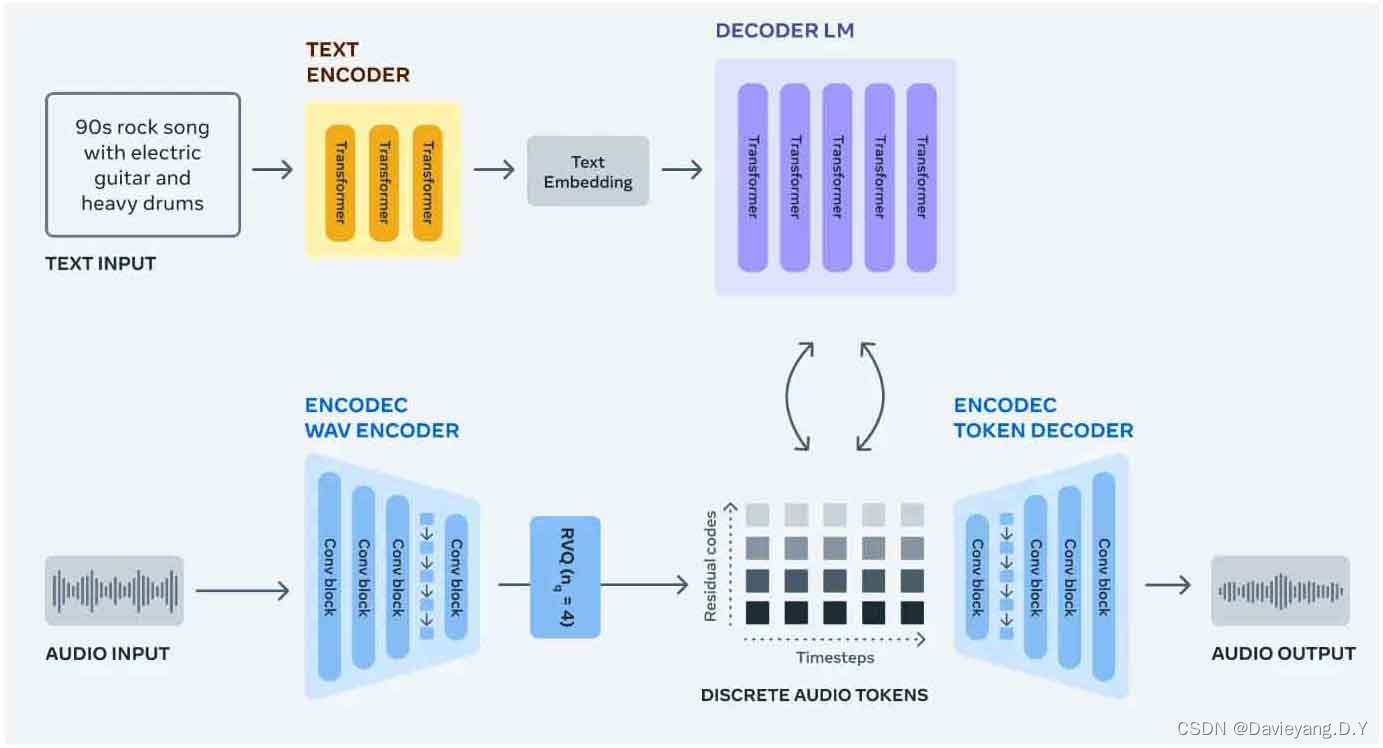
使用的是开源模型MusicGen,它可以根据文字描述或者已有旋律生成高质量的音乐(32kHz),其原理是通过生成Encodec token然后再解码为音频,模型利用EnCodec神经音频编解码器来从原始波形中学习离散音频token。EnCodec将音频信号映射到一个或多个并行的离散token流。然后使用一个自回归语言模型来递归地对EnCodec中的音频token进行建模。生成的token然后被馈送到EnCodec解码器,将它们映射回音频空间并获取输出波形。最后,可以使用不同类型的条件模型来控制生成

准备运行环境
拷贝模型文件
import moxing as mox
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/MusicGen/model/', 'model')
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/course/ModelBox/opus-mt-zh-en', 'opus-mt-zh-en')
mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/course/ModelBox/frpc_linux_amd64', 'frpc_linux_amd64')
基于Python3.9.15 创建虚拟运行环境
!/home/ma-user/anaconda3/bin/conda create -n python-3.9.15 python=3.9.15 -y --override-channels --channel http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
!/home/ma-user/anaconda3/envs/python-3.9.15/bin/pip install ipykernel
修改Kernel文件
import json
import os
data = {
"display_name": "python-3.9.15",
"env": {
"PATH": "/home/ma-user/anaconda3/envs/python-3.9.15/bin:/home/ma-user/anaconda3/envs/python-3.7.10/bin:/modelarts/authoring/notebook-conda/bin:/opt/conda/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/home/ma-user/modelarts/ma-cli/bin:/home/ma-user/modelarts/ma-cli/bin:/home/ma-user/anaconda3/envs/PyTorch-1.8/bin"
},
"language": "python",
"argv": [
"/home/ma-user/anaconda3/envs/python-3.9.15/bin/python",
"-m",
"ipykernel",
"-f",
"{connection_file}"
]
}
if not os.path.exists("/home/ma-user/anaconda3/share/jupyter/kernels/python-3.9.15/"):
os.mkdir("/home/ma-user/anaconda3/share/jupyter/kernels/python-3.9.15/")
with open('/home/ma-user/anaconda3/share/jupyter/kernels/python-3.9.15/kernel.json', 'w') as f:
json.dump(data, f, indent=4)
print('kernel.json文件修改完毕')
安装依赖
!pip install --upgrade pip
!pip install torch==2.0.1 torchvision==0.15.2
!pip install sentencepiece
!pip install librosa
!pip install --upgrade transformers scipy
!pip install gradio==4.16.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
!cp frpc_linux_amd64 /home/ma-user/anaconda3/envs/python-3.9.15/lib/python3.9/site-packages/gradio/frpc_linux_amd64_v0.2
!chmod +x /home/ma-user/anaconda3/envs/python-3.9.15/lib/python3.9/site-packages/gradio/frpc_linux_amd64_v0.2
模型测试
模型推理
#@title Default title text
import torch
from transformers import AutoProcessor, MusicgenForConditionalGeneration, pipeline
zh2en = pipeline("translation", model="./opus-mt-zh-en")
prompt = "六一儿童节 男孩专属节奏感强的音乐"
prompt = zh2en(prompt)[0].get("translation_text")
print(prompt)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
processor = AutoProcessor.from_pretrained("./model/")
model = MusicgenForConditionalGeneration.from_pretrained("./model/")
model.to(device)
inputs = processor(
text=[prompt],
padding=True,
return_tensors="pt",
).to(device)
# max_new_tokens对应生成音乐的长度,1024表示生成20s长的音乐;
# 目前最大支持生成30s长的音乐,对应max_new_tokens值为1536
audio_values = model.generate(**inputs, max_new_tokens=1024)
生成音频文件
from IPython.display import Audio
sampling_rate = model.config.audio_encoder.sampling_rate
if torch.cuda.is_available():
audio_data = audio_values[0].cpu().numpy()
else:
audio_data = audio_values[0].numpy()
Audio(audio_data, rate=sampling_rate)
保存文件
import scipy
sampling_rate = model.config.audio_encoder.sampling_rate
if torch.cuda.is_available():
audio_data = audio_values[0, 0].cpu().numpy()
else:
audio_data = audio_values[0, 0].numpy()
scipy.io.wavfile.write("music_out.wav", rate=sampling_rate, data=audio_data)
")
图形化生成界面应用
import torch
import scipy
import librosa
from transformers import AutoProcessor, MusicgenForConditionalGeneration, pipeline
def music_generate(prompt: str, duration: int):
zh2en = pipeline("translation", model="./opus-mt-zh-en")
token = int(duration / 5 * 256)
print('token:',token)
prompt = zh2en(prompt)[0].get("translation_text")
print('prompt:',prompt)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
processor = AutoProcessor.from_pretrained("./model/")
model = MusicgenForConditionalGeneration.from_pretrained("./model/")
model.to(device)
inputs = processor(
text=[prompt],
padding=True,
return_tensors="pt",
).to(device)
audio_values = model.generate(**inputs, max_new_tokens=token)
sampling_rate = model.config.audio_encoder.sampling_rate
if torch.cuda.is_available():
audio_data = audio_values[0, 0].cpu().numpy()
else:
audio_data = audio_values[0, 0].numpy()
scipy.io.wavfile.write("music_out.wav", rate=sampling_rate, data=audio_data)
audio,sr = librosa.load(path="music_out.wav")
return sr, audio
import gradio as gr
with gr.Blocks() as demo:
gr.HTML("""文本生成音乐
""")
with gr.Row():
with gr.Column(scale=1):
prompt = gr.Textbox(lines=1, label="提示语")
duration = gr.Slider(5, 30, value=15, step=5, label="歌曲时长(单位:s)", interactive=True)
runBtn = gr.Button(value="生成", variant="primary")
with gr.Column(scale=1):
music = gr.Audio(label="输出")
runBtn.click(music_generate, inputs=[prompt, duration], outputs=[music], show_progress=True)
demo.queue().launch(share=True)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Running on local URL: http://127.0.0.1:7860
IMPORTANT: You are using gradio version 4.16.0, however version 4.29.0 is available, please upgrade.
--------
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Running on public URL: http://cd3ee3f9072d7e8f5d.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (http://huggingface.co/spaces)
点击链接打开图形界面,如图所示
")