Kafka面试题及答案
Kafka是一个开源的分布式流处理平台,被广泛应用于大数据领域。由于其高性能、高可靠性和可扩展性,Kafka成为了很多公司工程师面试的热门话题。如果你准备面试Kafka相关的职位,下面是一些你可能会遇到的常见问题及其解析。
Kafka的基本概念是什么?
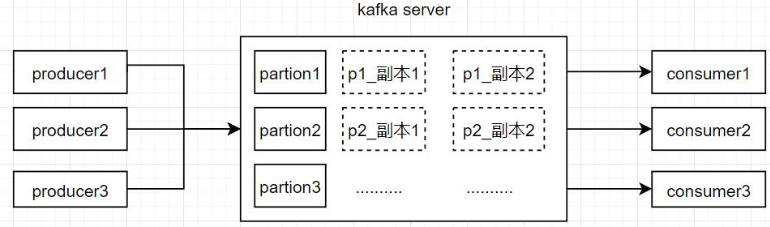
Kafka是一个分布式流处理平台,它通过高吞吐量、低延迟和分布式存储来处理大规模的实时数据流。Kafka的核心概念包括生产者、消费者、主题、分区和副本。生产者将消息推送到主题,消费者从主题订阅并消费消息。主题被分为多个分区,每个分区可以有多个副本来提供高可用性和容错性。
Kafka的消息保证有哪些级别?
Kafka提供了三个消息保证级别:最多一次(At most once)、最少一次(At least once)和正好一次(Exactly once)。最多一次是指消息可能会丢失,最少一次是指消息可能会重复,而正好一次是指消息不会丢失也不会重复。
Kafka如何保证高可用性?
Kafka通过将主题分为多个分区,并在多个服务器上复制这些分区的副本来实现高可用性。当一个副本失败时,Kafka会自动将其他副本晋升为领导者,并选择新的副本作为追随者。
Kafka如何实现水平扩展?
Kafka通过增加分区和副本来实现水平扩展。增加分区可以提高吞吐量和并行处理能力,增加副本可以提高可用性和容错性。同时,Kafka还提供了消费者组的概念,可以将消费者分组并为每个分组分配一部分分区来实现负载均衡。
Kafka如何处理消息的顺序性?
Kafka保证了每个分区内的消息顺序性,即同一分区内的消息会按照生产的顺序进行消费。但不同分区之间的消息顺序是不保证的,因为分区之间是并行处理的。
Kafka如何处理消息丢失的问题?
Kafka通过将消息持久化到磁盘,并复制到多个副本来避免消息丢失。当消息被生产者发送后,会等待在所有副本中得到确认(acks)后才会发送确认。如果有副本失败,Kafka会自动从其他副本中获取消息进行恢复。
Kafka和其他消息队列的比较有哪些?
与传统的消息队列相比,Kafka具有更高的吞吐量、更低的延迟和更好的持久性。Kafka的设计目标是支持多消费者的高吞吐量流式数据处理,而传统的消息队列更适合点对点的异步通信。此外,Kafka还支持分布式、水平扩展和容错能力。
总结
Kafka作为一个强大的分布式流处理平台,已经被广泛应用于大数据领域。在面试中,理解Kafka的基本概念、消息保证级别、高可用性和水平扩展等核心特性是非常重要的。同时,对于Kafka和其他消息队列的比较也是一个常见的面试题目。希望通过这篇博客,能够对准备面试Kafka相关职位的人有所帮助。