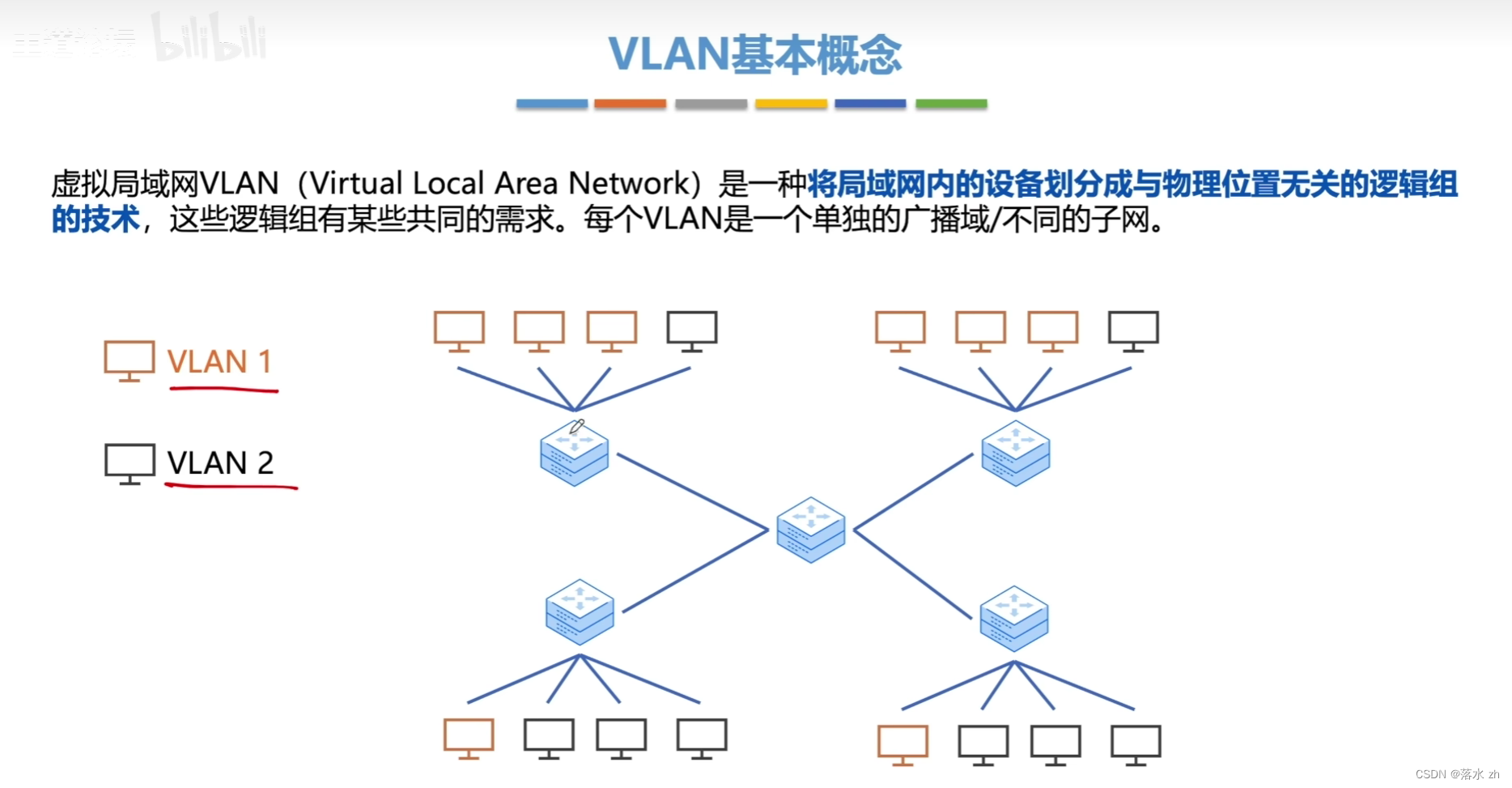
Python爬虫之BeautifulSoup保存图片到本地
在网络爬虫的世界里,文字是丰富的养分,而图片则是色彩缤纷的果实。无论你是在收集艺术作品、建立产品目录,还是只是想保存那些令人惊叹的旅行照片,从网页上抓取并保存图片都是一项常见而重要的任务。今天,我们将深入探讨如何使用Python优雅且高效地将这些数字图像从浩瀚的互联网转移到你的本地磁盘上。
为什么要保存网页图片?
在开始技术细节之前,让我们先思考一下为什么我们要这么做:
- 数据集构建:机器学习研究者经常需要大量的图像来训练模型,比如物体识别或风格转换算法。
- 内容聚合:想象一个展示全球街头艺术的网站,你需要从各种博客和社交媒体平台收集图片。
- 备份与存档:也许你是一个摄影师,想备份所有发布在你网站上的照片。
- 离线访问:保存旅游目的地的图片,以便在没有网络时进行参考。
- 比较研究:收集多年来同一产品的图片,研究其设计演变。
无论理由是什么,技术挑战都是相似的:识别、下载并适当地组织这些图片。
步骤1:定位图片
在开始下载之前,我们需要在网页的HTML中找到图片链接。这就是我们上一篇博客中讨论的BeautifulSoup大显身手的地方。
import requests
from bs4 import BeautifulSoup
# 假设我们在爬一个旅游博客
url = "http://travelblog.com/japan-2024/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有![]() 标签
images = soup.find_all('img')
# 提取src属性
image_urls = [img['src'] for img in images if 'src' in img.attrs]
print(f"找到 {len(image_urls)} 张图片")
for url in image_urls[:3]: # 只显示前3个
print(f" - {url}")
标签
images = soup.find_all('img')
# 提取src属性
image_urls = [img['src'] for img in images if 'src' in img.attrs]
print(f"找到 {len(image_urls)} 张图片")
for url in image_urls[:3]: # 只显示前3个
print(f" - {url}")
这段代码使用BeautifulSoup找到所有的src属性,这通常是图片文件的URL。但要小心,有时图片可能在其他属性中,如data-src(用于延迟加载)或srcset(用于响应式图片)。
# 更全面的方法
for img in images:
src = img.get('src') or img.get('data-src') or img.get('srcset', '').split()[0]
if src:
image_urls.append(src)
步骤2:构建完整的URL
从
- 绝对路径:
http://example.com/images/photo.jpg - 根相对路径:
/images/photo.jpg - 协议相对路径:
//example.com/images/photo.jpg - 相对路径:
../images/photo.jpg
我们需要确保所有的URL都是完整的绝对路径:
from urllib.parse import urljoin
base_url = "http://travelblog.com/japan-2024/"
full_urls = [urljoin(base_url, img_url) for img_url in image_urls]
print("完整的图片URL:")
for url in full_urls[:3]:
print(f" - {url}")
urljoin函数非常智能,它知道如何正确地组合基础URL和相对路径。
步骤3:下载图片
现在我们有了完整的图片URL列表,是时候将它们下载到本地了。我们将使用requests库来完成这个任务:
import os
# 创建一个目录来存储图片
if not os.path.exists("japan_photos"):
os.makedirs("japan_photos")
# 下载每张图片
for i, url in enumerate(full_urls):
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 从URL中提取文件名,如果没有则使用索引
filename = os.path.basename(url) or f"{i+1}.jpg"
# 拼接完整的文件路径
filepath = os.path.join("japan_photos", filename)
# 以二进制模式写入文件
with open(filepath, 'wb') as f:
f.write(response.content)
print(f"保存 {filename}")
else:
print(f"无法下载 {url}")
这个脚本做了以下几件事:
- 创建一个名为
japan_photos的目录来存储图片。 - 遍历每个图片URL并发送GET请求。
- 检查响应是否成功(状态码200)。
- 尝试从URL中提取文件名,如果不能则使用索引。
- 构建完整的文件路径。
- 以二进制模式写入图片数据。
注意,我们使用os.path模块来处理文件路径,这使得代码在Windows、macOS和Linux上都能正常工作。
高级技巧
1. 异步下载
当处理大量图片时,同步下载可能会很慢。使用aiohttp库进行异步下载可以显著提升速度:
import asyncio
import aiohttp
async def download_image(session, url, path):
async with session.get(url) as response:
if response.status == 200:
with open(path, 'wb') as f:
f.write(await response.read())
print(f"保存 {path}")
async def main():
async with aiohttp.ClientSession() as session:
tasks = [download_image(session, url, f"japan_photos/{i+1}.jpg")
for i, url in enumerate(full_urls)]
await asyncio.gather(*tasks)
asyncio.run(main())
2. 避免重复下载
如果你的爬虫会多次访问同一网站,你可能会重复下载相同的图片。使用图片的SHA-256哈希作为唯一标识符可以避免这种情况:
import hashlib
def get_image_hash(data):
return hashlib.sha256(data).hexdigest()
# 在保存图片时
image_data = response.content
image_hash = get_image_hash(image_data)
filename = f"{image_hash}.jpg"
if not os.path.exists(f"japan_photos/{filename}"):
with open(f"japan_photos/{filename}", 'wb') as f:
f.write(image_data)
3. 尊重robots.txt
爬虫应该遵守网站的robots.txt文件,它指定了哪些区域是允许爬取的。使用robotparser模块:
import robotparser
rp = robotparser.RobotFileParser()
rp.set_url("http://travelblog.com/robots.txt")
rp.read()
if rp.can_fetch("*", "http://travelblog.com/japan-2024/"):
# 继续爬取
else:
print("此页面不允许爬取")
4. 添加请求头和延迟
一些网站可能会阻止未带请求头的请求,或者如果请求太频繁。设置User-Agent和添加延迟可以帮助规避这些问题:
import time
import random
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
for url in full_urls:
response = requests.get(url, headers=headers)
# ... 保存图片 ...
# 随机延迟1到3秒
time.sleep(random.uniform(1, 3))
错误处理和恢复
网络爬虫总是会遇到问题:网站可能会暂时离线,图片可能已被移动或删除,或者你的IP可能被暂时封禁。健壮的错误处理是关键:
import requests.exceptions
try:
response = requests.get(url, timeout=10)
# ... 处理响应 ...
except requests.exceptions.Timeout:
print(f"{url} 请求超时")
except requests.exceptions.ConnectionError:
print(f"无法连接到服务器")
except requests.exceptions.HTTPError as e:
print(f"HTTP错误: {e}")
except Exception as e:
print(f"发生未知错误: {e}")
# 可以将错误的URL保存到一个文件中以后重试
with open("failed_urls.txt", "a") as f:
f.write(f"{url}
")
道德和法律注意事项
在我们结束之前,必须强调网络爬虫的道德和法律方面:
- 版权:不是所有在网上找到的图片都是免费使用的。确保你有权下载和使用这些图片。
- 带宽成本:大规模下载图片会增加网站的带宽成本。对小型网站要特别小心。
- 服务条款:许多网站在其服务条款中禁止抓取。总是要检查这些条款。
- 个人隐私:如果你在下载可能包含个人信息的图片(如个人照片),要特别注意隐私问题。
- 商业用途:如果你打算将这些图片用于商业目的,几乎总是需要明确的许可。
我的建议?首先尝试通过官方API或与网站所有者联系来获取你需要的图片。只有在这些选项不可行且你确定你的行为是道德和合法的情况下,才应该采取网络爬虫的方式。
总结
从网页上抓取并保存图片是一项技术性和道德性并重的任务。技术上,它涉及定位图片链接、构建完整URL、高效下载以及处理各种边缘情况和错误。我们已经看到如何使用强大的Python库如BeautifulSoup、requests和aiohttp来完成这些任务,甚至学习了一些高级技巧来优化性能和可靠性。
但技术只是故事的一半。作为开发者和数据科学家,我们有责任以尊重、合法且道德的方式使用这些工具。网络不仅仅是数据的海洋;它也是创意、知识产权和个人隐私的家园。优雅地下载图片不仅意味着编写智能高效的代码,还意味着明智且合乎道德地选择我们的目标和方法。